- Emergence?
- Machine Translation: "My name is Rich" &rarr "Je m'appelle Rich"
- Speech Recognition: a machine learns to wreck a nice beach
- Computational morpholgy
- Word-sense disambiguation and translational word-choice
![]()
Solve for arbitrary language pairs, with little or no supervision
- Elman "Learning and development in neural networks: the
importance of starting small"
- SRN given randomly generated sentences according to a simple grammar:
boys who chase dogs see girls . girl who boys who feed cats walk . cats chase dogs . mary feeds john . dogs see boys who cats who marry feeds chase .
- Subject/verb agreement requires long-distance dependency:
dogs see boys who cats who marry feeds chase .
- Experiment: Generate 10K sentences (number used by
Elman) according to grammar. Can interesting insights be
discovered?
- Is this emergence?
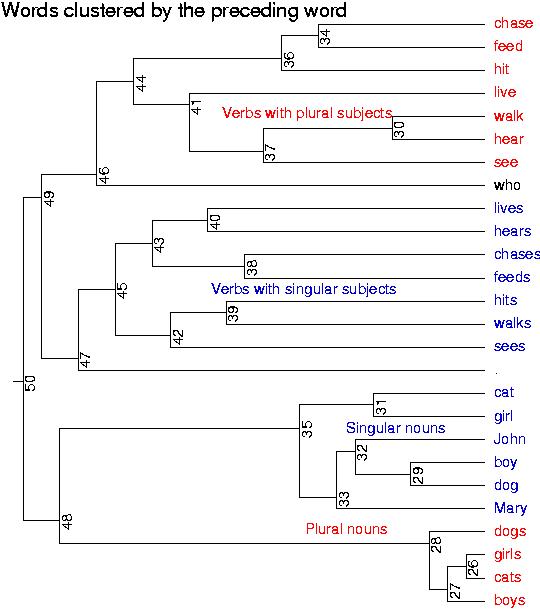
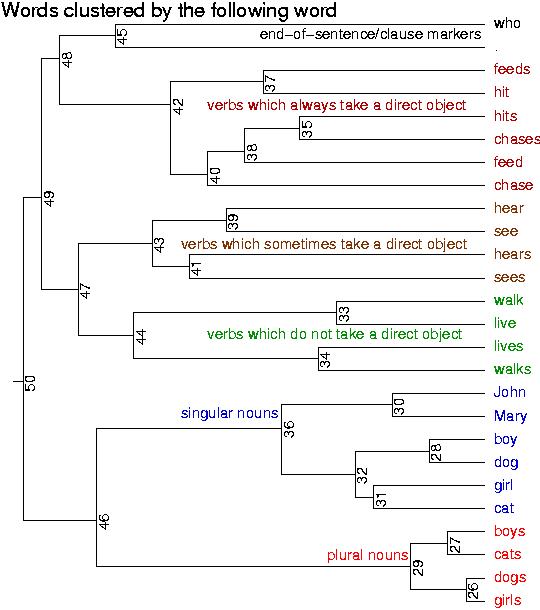
- Start with the British National Corpus (115 million words / 6 million sentences / publications since 1960 )
- Cluster all the verbs by the three following words.
- What do we expect? All the verbs that take direct
objects together?
- Clustered results: rbtree30.pdf &
rbtree100.pdf
- Note that we could have also clustered on previous there
words (results not included).
- Is this emergence?
- A note about memory requirements.
- Storing the co-occurence matrix above requires storing
(# verbs) * (# words) integers.
- In this case, 3470 * 330328 = 1,146,238,160, or about 4.5G
of memory.
- (Though this data is very sparse and only requires
about 30M in practice.)
The SRN we've seen (input layer = 3470, waist layer = 10, hidden layer = 70, waist layer = 10, output layer = 3470) requires storage of 84,286,300,000 floating point values, or about 337G of memory.And that's not even mentioning anything about the how we will input the non-verb words which could require something like 768,440,705,088,000 floating point values. Do you have 30,736G of memory?- We decided the above two arguments were not correct.
(Jason Eisner's LSA slides)We didn't talk about this.
- Storing the co-occurence matrix above requires storing
(# verbs) * (# words) integers.
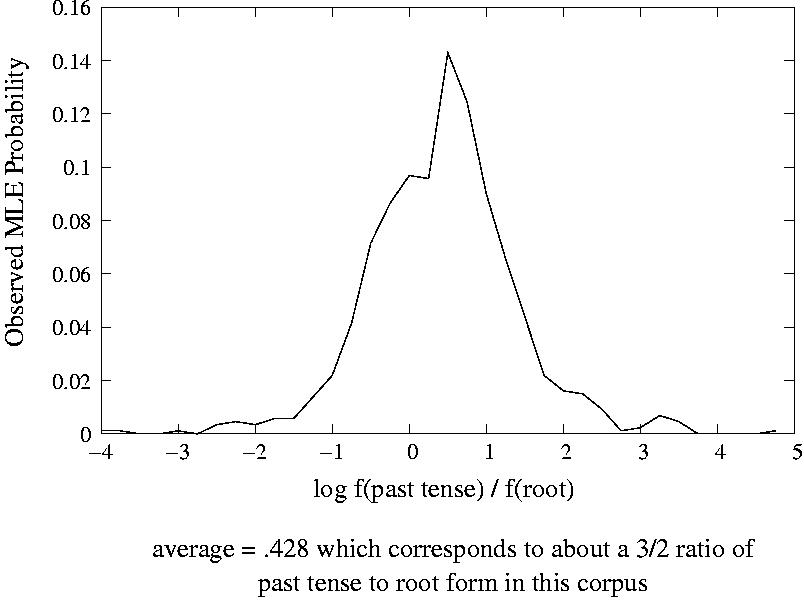
- Forms are used in a consistent ratio relative to other variants of the same form.
- All this and we haven't even looked at spelling!
- some slides if you're still awake
- Word-sense disambiguation and translational selection
- Sentiment classification